Data comes in all forms. Lately, we’ve been going over mostly numerical and categorical data. Even though the categorical data contains words, we transform it into numerical data for our algorithms. However, what if your data is only words? That’s where natural language processing comes in, and in this post, we’ll go over the basics of processing text by using data from Twitter as an example that we got from a previous post. We’ll also be using the NLTK (natural language toolkit) package in Python that gives us a lot of help in processing and cleaning our text data.
We’ll be using the same Twitter data we got in the post on using the Text Analytics API to detect languages of our tweets.
Like always, the code for NLTK is on GitHub.
Natural Language Processing Concepts
After getting our text data, we have to do that all-important cleaning of the data so we can do proper analysis on it. Since text data isn’t as structured as the numerical data we’ve been working with before, there’s quite a few steps to take to get it into a clean state.
With most of this processing, we’re going to utilize the NLTK package for Python. This package will help a lot in terms of cleaning your text data. If you’ve never used this package before (which is included in the Anaconda distribution), you will need to execute the download method after importing.
import nltk
nltk.download()
This will show a GUI similar to this:
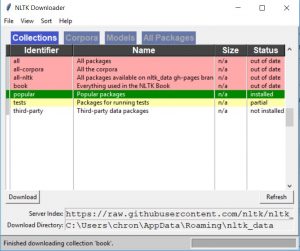
This will allow you to download extra packages for NLTK including WordNet and a lot of text samples (also called corpra, which is a body of text) you can play around with, including some books from Project Gutenberg and movie reviews.
You may have noticed the “book” collection, and as you can guess, there is a book for NLTK. You can actually read the online version for free, and it’s been updated to Python 3.
Tokenizing
The first thing we must do to our data is to tokenize it. That is, break up paragraphs into sentences (sentence tokenization) or break up sentences into single words (word tokenization).
For sentence tokenization, use the sent_tokenize method. Most tweets are only one sentence long, so there may not be much of a difference in the tokenization here.
[nltk.sent_tokenize(item) for item in df[“text”].values]
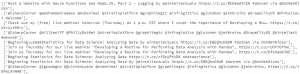
For the rest of this post, we’ll be using the output from the word_tokenize method.
tokens = [nltk.word_tokenize(item) for item in df[“text”].values]
tokens

Now, we have some text data we can start to work with for the rest of our cleaning.
Removing Punctuation
In our word tokenization, you may have noticed that NLTK parsed out punctuation such as : and @, which are commonly found in tweets. Punctuation is just noise, and it’s best to clean them out of our data.
To clean our punctuation out, we’ll use a regular expression and Python’s built-in string.punctuation attribute, which includes all punctuation.
import string
import re
regex = re.compile(f'[{re.escape(string.punctuation)}]’)
To create our regular expression, we use Python’s string interpolation. A string that starts with an f on the outside indicates to Python that we want to format it. Anything in curly braces will then get executed and Python will build the string from the output.
Using the regex we can now use a nested list comprehension to replace any punctuation with empty strings.
[regex.sub(u”, word) for words in tokens for word in words if not regex.sub(u”, word) == u”]

Removing Stop Words
Stop words are words that have no meaning but they are useful in a language to help put sentences together. They are usually the most popular words, such as “the,” “and,” and “a.” For natural language processing, these words can add noise in a similar way that punctuation can.
NLTK has its own list of stop words, and you are free to use your own list or just add to what NLTK provides. In fact, we’ve added “via” as a stop word. Since it’s a Python list, we can just append to it.
from nltk.corpus import stopwords
stop_words = stopwords.words(“english”)
stop_words.append(“via”)
words = [token for token in tokens_without_punctuation if token not in stop_words]
words[:15]

Notice how “a,” “and,” and “with” are now gone from our list of words.
Removing Links
Since this is Twitter data, there’s going to be a good chance that tweets will have links in them. We’ll go back to using regex and remove anything that starts with “http,” “https,” and since Twitter changes links, we’ll check for text that starts with “tc.”
import re
regex = re.compile(‘http\S+’)
tokens_without_links = [regex.sub(u”, word) for word in words if not regex.sub(u”, word) == u” and not word.startswith(“tc”)]
tokens_without_links[:15]

Notice the “https” and the string starting with “tco” has been removed from our list of words.
Stemming
Applying stemming on our words allows us to reduce the amount of words to a single “stem” of a word. For example, if my list of words contains “deployment” and “deploying,” applying stemming to it will reduce them to a single word: “deploy.” This is another way of reducing noise in our text data.
NLTK comes to the rescue and offers us a way to stem our text data.
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
stemmed_words = [stemmer.stem(word) for word in tokens_without_links]
stemmed_words[:10]

Notice that it changed “logging” to “log” as well as “functions” to “function.” However, you may also notice something weird happened. Some words were changed to words that don’t exist, such as “website” changing to “websit” and “azure” changing to “azur.” Stemming algorithms work by stripping out suffixes so sometimes that stripping results in words that don’t exist in the language.
Lemmatizing
Other than applying stemming to our data, a more sophisticated way to reduce our words to a single word is to apply a lemmatization algorithm to it. This works differently, and better, than stemming since it can do a dictionary lookup on each word rather than just stripping off suffixes.
NLTK has algorithms for lemmatizing on our text data.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(word) for word in tokens_without_links]
lemmatized_words[:15]

Processing Text in Azure Machine Learning
Now that we know the steps needed to pre-process text data (and how to do them with NLTK), let’s see how we can do the same in Azure Machine Learning.
We can upload a CSV of our original tweet data (which is in GitHub) by going to “New” and then “New dataset.”

Once it’s uploaded, find it in the “My Datasets” portion on the left and drag it out into the canvas.
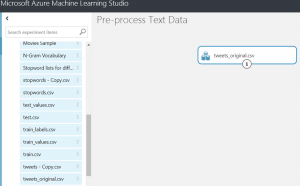
Azure ML offers quite a lot of things we can do with text. The only one we’ll go through in this post is the “Preprocess Text” module.
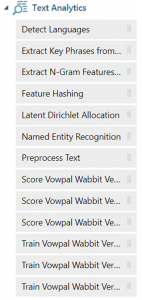
Drag the “Preprocess Text” module over to the canvas and connect it to the tweet data set.
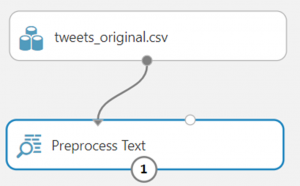
Highlight the “Preprocess Text” module, and on the right, you’ll see a bunch of properties. A good many of those may look familiar.
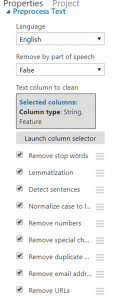
Click to launch the column selector so we can tell the module which column to apply all the text transformations on. Tell it to use the “text” column by name.

Click to run at the bottom and wait for the processing to complete. Then right click in the module and click “Visualize.”

And that’s all! Most of the cleaning of the text has been done. That was much easier and quicker than going through NLTK and coding all these cleaning tasks by hand.
In this post, we briefly went over using parts of the NLTK package to clean our text data in a way to get it ready for analysis or even to use it to build machine learning models. We also showed how to do the same kind of pre-processing on text data but in a much easier way with Azure Machine Learning with the “Preprocess Text” module.
Here are some other resources on Azure Machine Learning, Cognitive Services, & Data Science:
Save and Read Models in ML.NET
Developing a Routine for Performing Data Analysis with Pandas Webinar
An Overview of Azure Databricks
Using the Cognitive Services Text Analytics API: Detecting Languages
Understanding Azure Machine learning Whitepaper
