With the announcement of the general availability of Azure Databricks, in this post we’ll take this opportunity to get a brief feel to what Azure Databricks is and what it can do.
What is Databricks?
Databricks is a data solution that sits on top of Apache Spark to help accelerate a business’ data analytics side by bringing together the data engineering, data science, and the business. Databricks accomplishes this by offering optimized performance, data transparency, and integrating workflows.
Here’s a 10,000 foot view of the problem Databricks is trying to solve:
Now imagine all of that on top of the Azure platform. Get ready for your data mind to be blown. In fact, no imagining is necessary, because we can do just that and see how easy it is to get started with a data solution with Azure Databricks.
Creating an Azure Databricks Service
In the Azure Portal, go to create a new resource and in the Data + Analytics section click on Databricks. Alternatively, you can just search for Databricks.
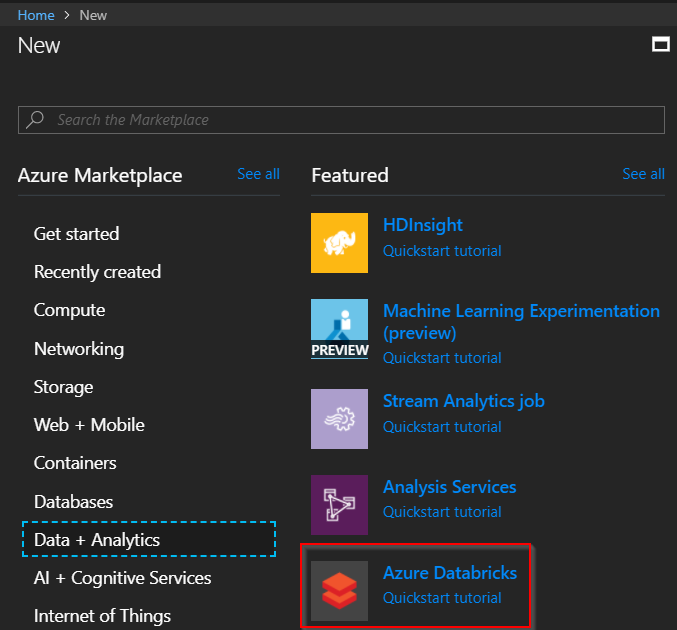
It’s quite simple to create a new Databricks service as there are only a few fields that are needed – workspace name, resource group, and pricing tier are the only ones that need to be filled in. The others can stay with the defaults.
Click “Create” and it may take a few minutes to deploy. Once it does you can go to the resource. You may notice there’s not too much to work with there. That’s due to Databricks having its own portal. Click on “Launch workspace” and you’ll be taken and signed in to your Databricks workspace.

There’s a lot we can do here! Let’s get into what all we can do in our workspace.
Creating a Spark Cluster
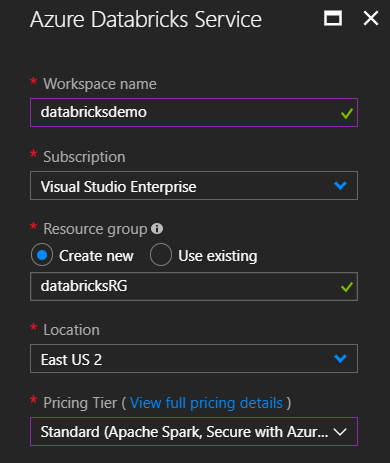
At the heart of Databricks is the Spark cluster. This is what will import any data as well as execute any of the code. To create a cluster, on the left navigation, click on “Clusters” and then “Create Cluster”.
The only piece that is required is to input a name for the cluster. But, there are a few options here you can change. Since it’s reported that the end of life for Python 2 is the very start of 2020, changing to Python 3 is recommended. There’s an option to auto-terminate after a set time of being idle, which can help with costs. You can even specify your own configurations for the Spark cluster.
After a few minutes your Spark cluster will be ready to be put to work. If you have the “Terminate after x minutes of inactivity” checked, then the cluster will terminate after being idle for that long. It won’t delete the cluster, so you are able to restart it if it does get terminated.
Importing Data
Naturally, we need some data in order to put our new Databricks Service to work. I’m going to use the salary data from a previous post on data analysis.
On the left navigation, click on “Data”. You’ll see two UI columns pop out. One is for databases, and the other is for tables.

Tables are just a way to make data available to anyone who has access to your cluster. To create a table click the “+” sign next to it and it will take you to a page where you have choices in which to import your data. To add a CSV, like we have, there’s a section below that allows us to upload a file. Upload a CSV and click on “Create Table with UI”. Select your cluster and click on “Preview table”. From here we can define how to load our CSV data into Databricks. We can give it a different name, tell if the first row contains the header, and tell Databricks what type each column is. Click “Create Table” to load in the data.
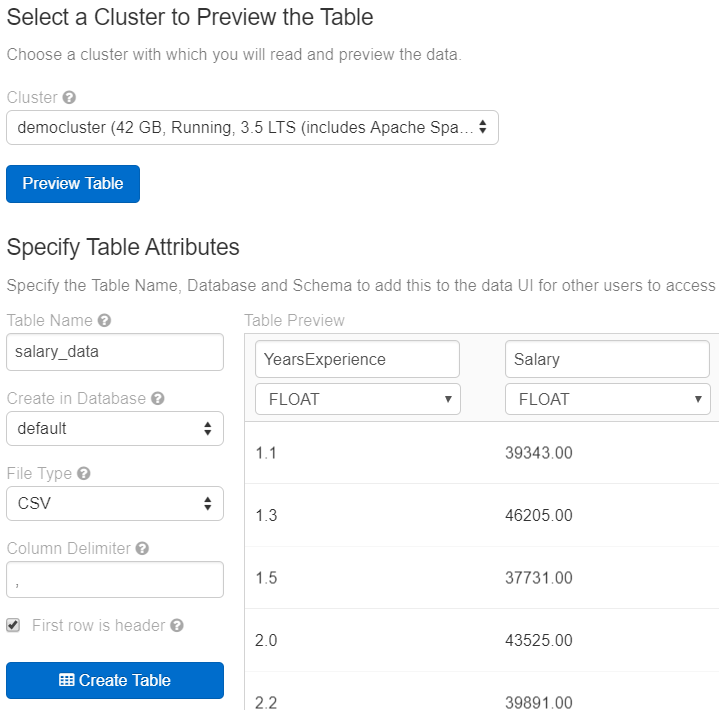
Now that we have our data in, let’s explore it some within a notebook.
Exploring Data
If a cluster is the heart of Databricks, then Notebooks would be the muscle as they do most of the heavy lifting of the data. Notebooks in Azure Databricks are similar to Jupyter notebooks, but they have enhanced them quite a bit. Due to these enhancements, exploring our data is much easier.
To create a notebook, on the left navigation click on “Workspace”. From there you’ll automatically go to the “Users” tab and your user workspace will be opened up. Click the down arrow next to your username, go to “Create” and then “Notebook”.
Give your notebook a name, what language you want to use (Databricks supports Python, R, Scala, and SQL), and what cluster to associate it to. From there we’re off to the races.
If you’ve used Jupyter notebooks before you can instantly tell that this is a bit different experience. Same concept of individual cells that execute code, but Databricks has added a few things on top of it.
Right off the bat Databricks gives you some variables that you can use, so keep these in mind:
- A
SparkContextassc

- A
HiveContextassqlContext

- A
SparkSessionasspark

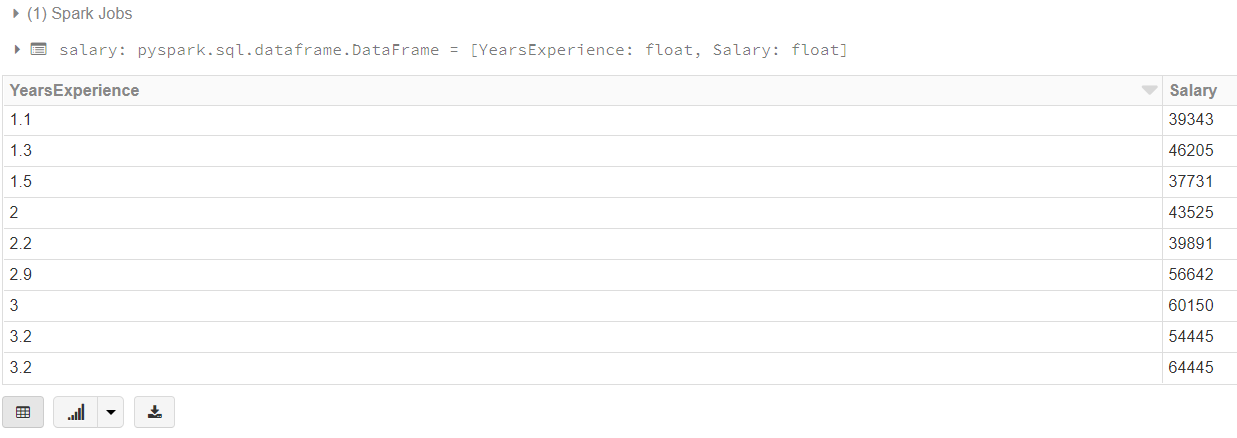
Let’s look at how we can load up the CSV we just added. We can use Spark SQL to load our data.
salary = spark.sql("select * from salarydata_csv")
display(salary)
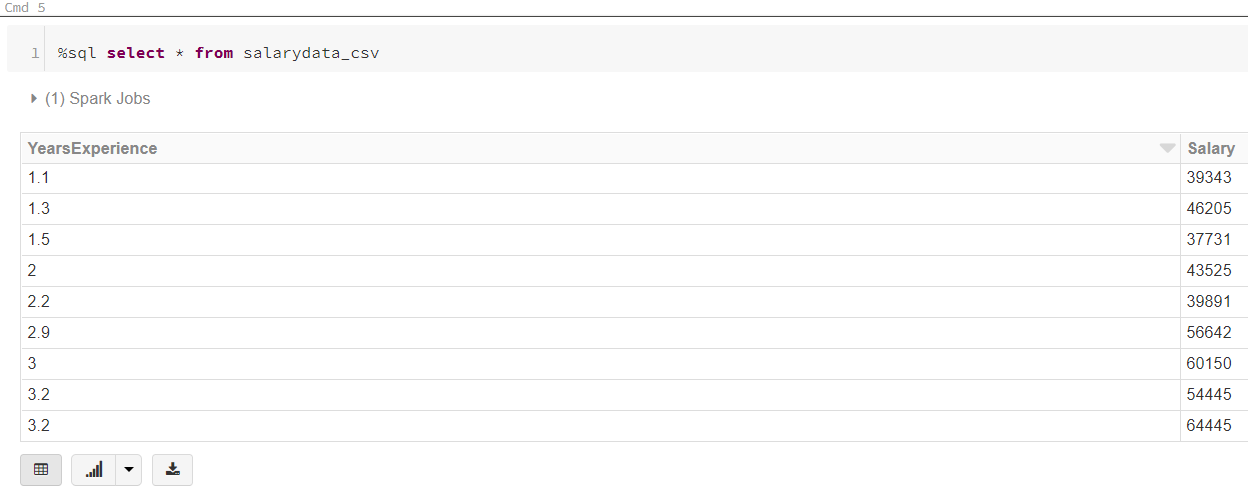
Oh, but you aren’t limited to using just one language in a notebook. We can mix languages in a single notebook. For instance we can directly use SQL to query our data.
%sql select * from salarydata_csv
Azure Databricks also includes sample data sets that we can get using the dbutils object.
display(dbutils.fs.ls("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/"))
Did you notice the graph icon at the bottom of each cell that returned data? This is another powerful feature of Databricks. You can instantly get different graphs for your data. Here’s the same data as a bar graph.
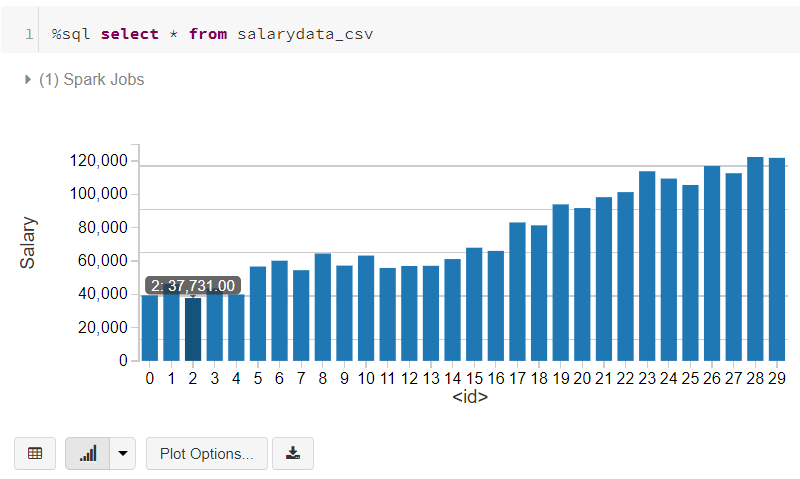
Feel free to use these to play around or upload your own data while taking your own tour of Azure Databricks.
In this post we briefly went over what Databricks is and how to create an instance of it through Azure. We also took a look at how Databricks’ notebooks provide a bit more functionality than what you get from regular Jupyter notebooks and how that can help you expore your data.
