When you think of data science and machine learning two programming languages are going to instantly pop into your mind: Python and R. These two languages are great and I love working with them, but coming from a .NET and C# background myself it would be nice to see some love for data science in the C# world. Well, now we have it with the announcement of ML.NET we can do just that!
In this post, we will go over ML.NET by creating a very simple application for it to train against some data, how to evaluate the model, and then how to predict on new data.
Note that ML.NET isn’t just for C#. Since it is a .NET language F# developers can use it as well. But we will concentrate on C# for this and other posts.
The code for this post is on GitHub.
Getting Setup with ML.NET
It’s actually fairly simple to get started using ML.NET. There are essentially two steps you need to make after you create a new project. First, you would need to get the NuGet package Microsoft.ML.
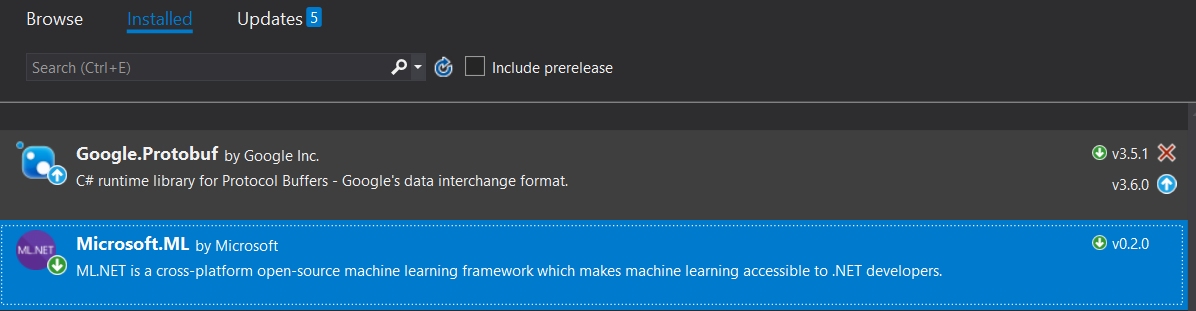
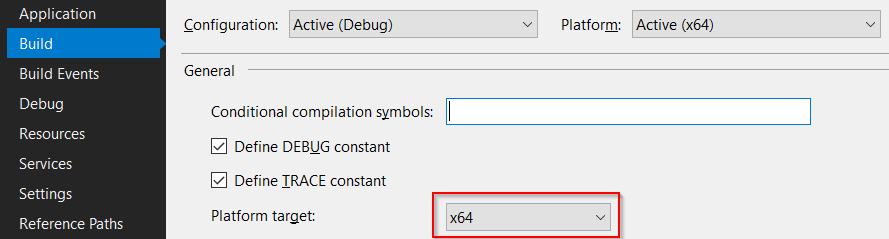
Second, you would have to update your build properties to target x64 since ML.NET doesn’t support x32.
And now we can start building our first machine learning pipeline to build our model. However, before we get started coding, let’s understand a bit about our data.
The Data Set
The data we’re going to be working in this post is one we’ve used before when we made a post with scikit-learn, which is a very simple data set that has two columns, YearsExperience and Salary.
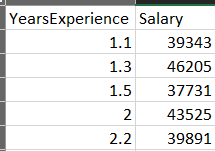
The data set isn’t very realistic to what you’ll get in the real world. That’s because I want to focus, as I did in the previous post, on the code to create the machine learning pipeline. We will have future posts on dealing with dirty data to come.
Modeling our Data
Before we can start creating our machine learning pipeline, we need to model our data so ML.NET can understand the structure of it, such as column data types. We need to do this twice, actually – once on our training data and again to model the data object when we predict on it.
We saw that our data has two columns so that’s all we would need to model for it in a class.
public class SalaryData
{
[Column("0")]
public float YearsExperience;
[Column("1", name: "Label")]
public float Salary;
}
There are two important parts here. First, we express columns of our data as fields in C#. If your data has headers to denote the names of the columns, it’s good practice to name your fields the same as your column headers. We also give it the data type of float. If you get these data types wrong you will receive a Bad value warning in the output when executing, so that’s something to look out for.
Second, we attach each field with the Column attribute from ML.NET. In each of these, we denote what position in the file each column is in. You may notice that this is zero based. In the Salary field we also give it a name of Label. This tells ML.NET that this is the column we want to predict on so it is our label column, or as I like to call it, our answer column.
Now that we have our data modeled for ML.NET we also have to model our what our prediction output should look like. This is in a similar fashion that we did before where we model the output data as C# fields.
public class SalaryPrediction
{
[ColumnName("Score")]
public float PredictedSalary;
}
Here, we match the same data type in our predicted salary to what we had from our field earlier that we marked as our label – Salary. We attach this with the ColumnName attribute to tell ML.NET that this is what we want to output as our scored value for when we call Predict on our model.
Create a Pipeline
Now that we have our data modeled we can start creating our machine learning pipeline. A pipeline is essentially a workflow that gets executed while training on the data. To create a new pipeline, just instantiate it.
var pipeline = new LearningPipeline();
From there we can start adding different parts to our pipeline with the Add method.
pipeline.Add(new TextLoader("SalaryData.csv").CreateFrom<SalaryData>(useHeader: true, separator: ','));
In our first item for our pipeline, we want to load in our data into ML.NET using the TextLoader class. In the constructor we put the path to our data and then we call the CreateFrom method on it, which takes a generic type. The type that you put here is the class that we modeled the data columns from in the previous section. For parameters to this method, we tell it to use the first row as a header and then tell it that our separator, or delimiter, for our file is a comma. By default, the separator is a tab (\t).
Now that our data is loaded into ML.NET we need to concatenate all of our columns except the label column into one column called “Features”.
pipeline.Add(new ColumnConcatenator("Features", "YearsExperience"));
To do that we use the ColumnConcatenator class. The constructor takes in two parameters. The first parameter is what the output column name should be once all the columns are concatenated. The second parameter is a params type. If you haven’t used that type before it lets you add as many parameters as you need. We only have one column in our data to create as our “Features” column, but you can put in as many columns as you need.
pipeline.Add(new ColumnConcatenator("Features", "Column1", "Column2", "Column3", "Column4"));
In our last entry into our pipeline, we’re going to tell ML.NET what machine learning algorithm we want to use. Since we want to predict a value to estimate a salary we would need to use a regression algorithm.
pipeline.Add(new GeneralizedAdditiveModelRegressor());
And that’s our pipeline! We can add as many items in our pipeline as we need, but this is all we need for our data.
Train Model
Now that we have our pipeline in place we’re ready to train our model. In ML.NET this is quite simple – just call the Train method on the pipeline. When we call the Train method we need to specify the types for the data model and the prediction.
var model = pipeline.Train<SalaryData, SalaryPrediction>();
When this runs you’ll see output similar to the below.
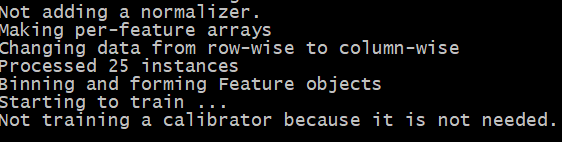
There’s a bit of noise here, but notice that it says “Processed 25 instances”. This tells us that it processed our data, all 25 rows, and there are no issues with it. Now let’s see how accurate our model is.
Evaluate Model
Now that our model is trained, we need to see how well it performs on test data. This is data that it hasn’t seen before during training. For our example, we will use a separate file for our test data. It’s not much, only five rows, but we can still use it to give us some metrics on our model.
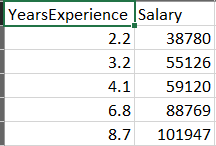
To evaluate our data we must read it in the same fashion that we did our training data.
var testData = new TextLoader("SalaryData-test.csv").CreateFrom<SalaryData>(useHeader: true, separator: ',');
But instead of adding it to a pipeline, we will now instantiate an instance of the RegressionEvaluator class.
var evaluator = new RegressionEvaluator();
And with that, we can call the Evaluate method and pass in our model and test data.
var metrics = evaluator.Evaluate(model, testData);
And that’s going to give us some interesting pieces of data that we can use to determine how well our model does.
Console.WriteLine($"Root Mean Squared: {metrics.Rms}");
Console.WriteLine($"R^2: {metrics.RSquared}");
![]()
First, there is root mean squared (RMS), also referred to as root mean squared error, measures the difference between the values we gave our model for training and the values that it predicted on our test data. This metric will tell you how off your predictions are when using this model. We received an RMS of 4417.59 which tells us that the model is, on average, off by that many dollars in a salary.
A few things to keep in mind when reading RMS. To use the RMS to measure your model’s performance, the closer to 0 it is then the better performance your model will have. If you have an RMS of 0, that indicates a perfect fit. However, you won’t see this in the real world and if you do, your model is most likely greatly overfitting.
Second, there is R squared. This measures the distance between the actual values and your model to determine how close or far away they are. The measurement is given between 0 and 1 with values closer to 0 indicates the model isn’t a very good fit. And values closer to 1 indicates the model is a good fit. Since we have an R squared value of 0.96 we can say our model is a pretty good fit.
However, within this post by Jim Frost on interpreting R squared, it does have its limitations. With that in mind, it is recommended to use RMS to get a more accurate view of how well your model performs.
These are only metrics for a linear regression algorithm, though. There are many other ways to evaluate your model performance depending on what kind of algorithm you use. For instance, if you’re using a classification algorithm then your metrics would be the Receiver operating characteristic (ROC) curve to measure the Area Under the Curve (AUD) as well as precision and recall.
Predict on Model
What good is a model if you can’t use it to predict with it? This is easy to do since all you need is to call the Predict method on your model.
private const int PREDICTION_YEARS = 8;
var prediction = model.Predict(new SalaryData { YearsExperience = PREDICTION_YEARS });
When you call Predict you do have to give it the type that you used as input when you trained on your model. In this case, we gave it the SalaryData type. Then we would fill in the fields on it that we used to create our features of the model. Since we only had one feature, YearsExperience, that’s all we need to fill in.
Once you call Predict it will give the output of the SalaryPrediction type. We can use that to show our predicted salary.
Console.WriteLine($"After {PREDICTION_YEARS} years you would earn around {String.Format("{0:C}", prediction.PredictedSalary)}");
![]()
And that’s all there is to it! That’s pretty simple, isn’t it?
In this post, we went over how to get started using the ML.NET framework and how to build your first pipeline where we got data, trained on that data to create a model, evaluated our model performance, and then made a prediction on our model. As ML.NET evolves as a framework we will have more to come on how to use it.
