Today’s post will cover Databricks Jobs. There is also the concept of a Spark Job which will be covered briefly to try to avoid confusion.
Spark Job
When running a Spark application there is the concept of a Spark job. At runtime, the Spark driver converts your Spark application into a job that is transformed into a directed acyclic graph (DAG) which is the execution plan. Each node within this DAG contains single or multiple Spark stages. Stages can be executed serially or in parallel and are made up of Spark Tasks (which is the smallest unit of execution) that map to a single core and single partition of data. This is how Spark achieves parallelism.
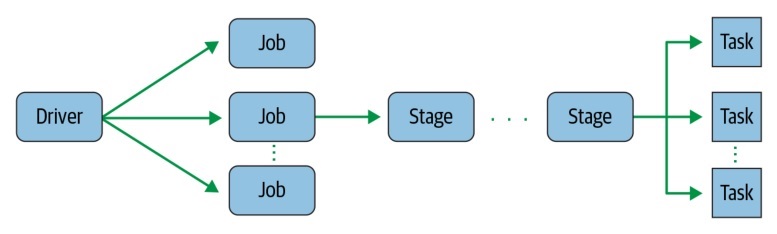
Databricks Jobs
A Databricks job, in contrast, is just a way to run code on a Databricks Cluster. Workloads can be scheduled or kicked off interactively from the notebook UI. A job can also be created and run using the Jobs API, CLI, or UI and monitored using the same tools (as well as email notifications). Until recently, Databricks jobs consisted of one Databricks task. However, there is a new preview feature that allows orchestration of multiple Databricks tasks. (Note that the tasks referred to here are Databricks Tasks and different from Spark Tasks. Here they can be thought of as Databricks job steps or notebooks that make up a job.)
Databricks Task Orchestration
Task Orchestration must be enabled for the whole workspace from the admin console. Tasks can be run sequentially or in parallel. The execution order of tasks is specified by dependencies between the tasks. This is a more in depth process that may be covered in a subsequent post.
Job Creation: Schedule a Notebook
One of the quickest ways to create a job from a notebook is to use the schedule dropdown at the top right. It will reveal the scheduling dialog where you can
- Name the job
- Specify if it is going to be scheduled or a manual job
- Specify the cluster that will run the job
- Custom parameters
- Configure alerts
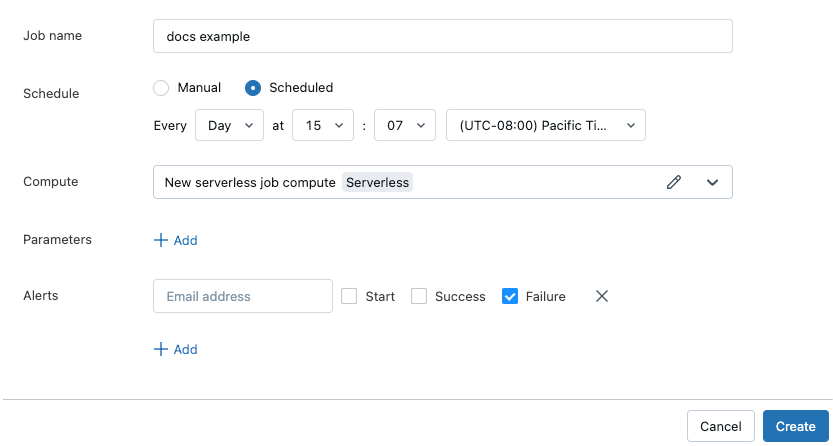
The ability to parameterize jobs is very valuable and will be covered in a future post on streaming and batch jobs.
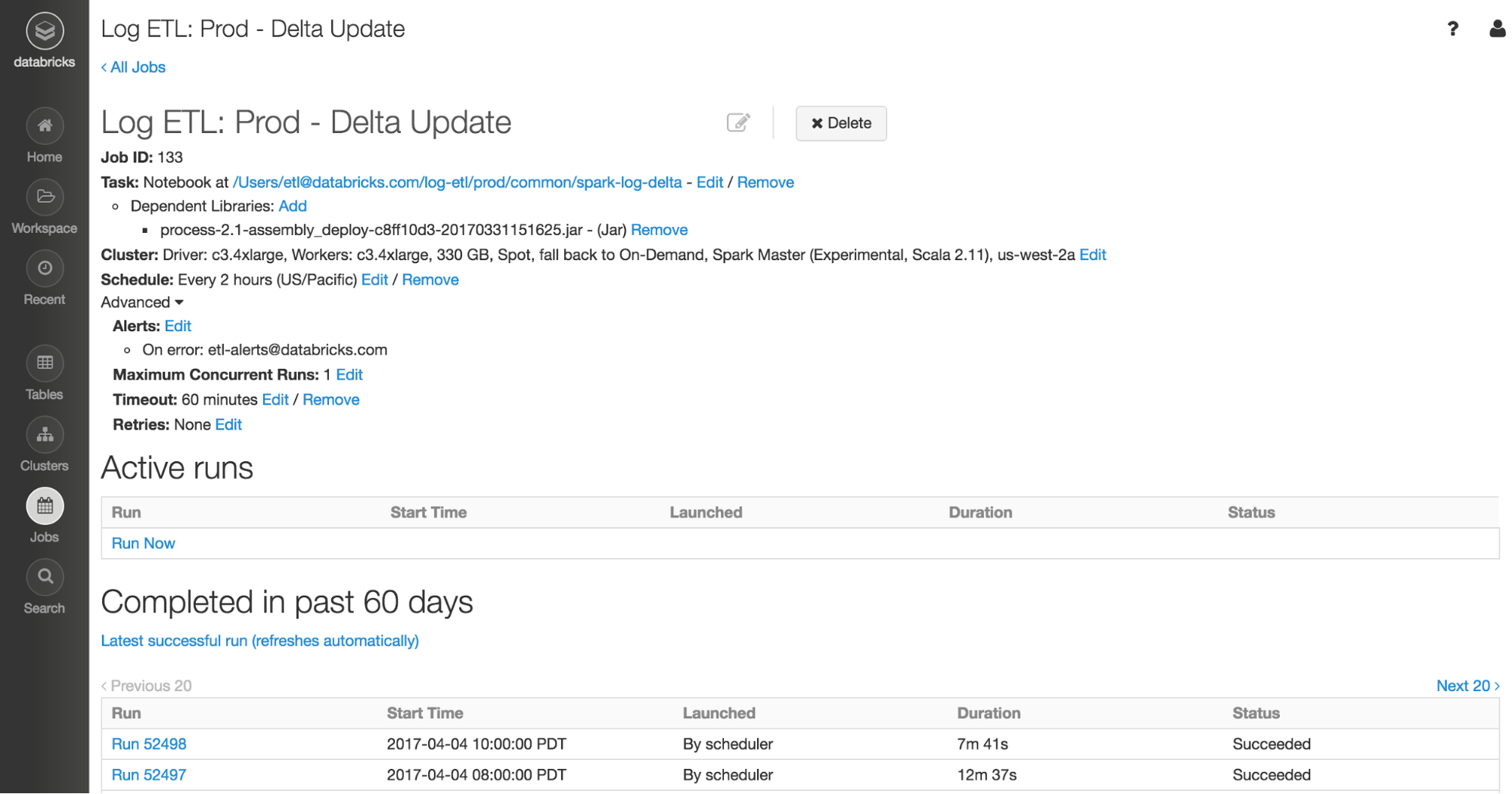
Jobs Sidebar
Your job is now created and can be viewed and run from the Jobs page within your workspace on the sidebar. Note that jobs can also be created here. Every job that was run contains a lot of valuable information about the job. The most basic information is if it Succeeded or Failed, the start time, and the duration. Clicking View Details will bring up an archived details of the job (if it was run in the past 60 days) including the Spark UI. This is very useful for tuning job clusters or diagnosing errors or issues.
For more information on Databricks Jobs, consult the official documentation which goes into more detail and is updated frequently.
