Let’s say you’ve been working on a machine learning model and your initial evaluation on test data looks good but is that the same kind of performance you’ll get once you deploy your model to take on actual data it hasn’t seen before?
This can happen if your model has overfitted to your data. We briefly talked about overfitting in a previous post so we won’t go into much detail for it here other than using a very effective way to determine if your model is overfitting – cross validation.
The code for ML.NET is on GitHub. If you’d rather watch how the below code works in ML.NET, I’ve also made a short video available.
What is Cross Validation?
Cross validation is a technique to validate your model’s performance. That is, a way to tell how well your model will perform on new data that it hasn’t seen on training data.
The way cross validation works is that it takes a subset of your training data and it uses that to evaluate the metrics of your model.
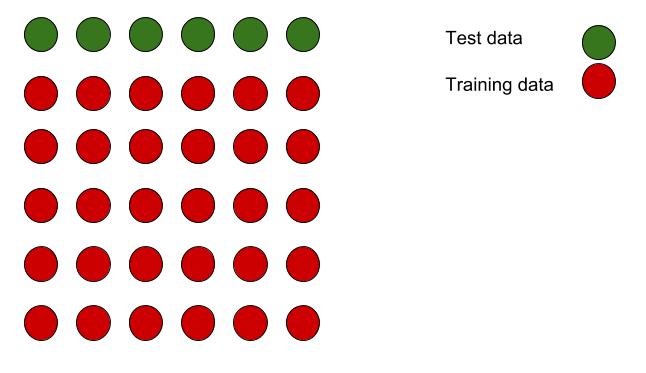
And it does it again on a new subset of your data.

And it will continue to do this on different subsets of your data. The number of times it does this can be configured.
The reason this is a good way to evaluate your models is that if you only evaluate on a certain part of your data, then that can produce a certain variance to your metric. That is, the subset you’re validating on may not have a good amount of data to give you an accurate evaluation of your model.
For a more detailed explanation with code in scikit-learn for cross validation, this video from Data School is a great one.
Cross Validation in ML.NET
We’ll use the same pipeline we did in our ML.NET introduction post before we can use cross validation.
var dataset = MLNetUtilities.GetDataPathByDatasetName("SalaryData.csv");
var pipeline = new LearningPipeline
{
new TextLoader(dataset).CreateFrom<SalaryData>(useHeader: true, separator: ','),
new ColumnConcatenator("Features", "YearsExperience"),
new GeneralizedAdditiveModelRegressor()
};
Once that’s been defined we can then easily use cross validation with the CrossValidator class.
var crossValidator = new CrossValidator()
{
Kind = MacroUtilsTrainerKinds.SignatureRegressorTrainer,
NumFolds = 5
};
Currently, you do need to specify the Kind property in the class. Otherwise, you may end up with an exception when you try to run the cross validation. There’s also an optional NumFolds property that you can fill out to tell the cross validation how many number of folds, or iterations, to go through your data to perform the cross validation.
Now that we have an instance of the CrossValidator class, we can use it to do our cross validation with the CrossValidate method. Notice that we have to, once again, specify our input and output classes. The only parameter it needs is the pipeline that we specified above.
var crossValidatorOutput = crossValidator.CrossValidate<SalaryData, SalaryPrediction>(pipeline);
The output has several collections, but since we have a regression algorithm in our pipeline, we’ll need to use the RegressionMetrics collection to judge our model’s performance. We can iterate on that to print out our different results.
crossValidatorOutput.RegressionMetrics.ForEach(m => Console.WriteLine(m.Rms));
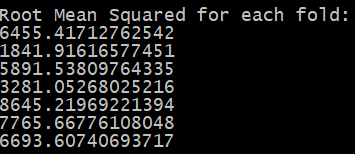
This isn’t bad output. We get a root mean squared for each iteration on our data. But this doesn’t tell us about the overall performance of our model. To do that, let’s take the average value of this output. And, just for kicks, we can do the same for R Squared, as well.
var totalR2 = crossValidatorOutput.RegressionMetrics.Sum(metric => metric.RSquared);
var totalRMS = crossValidatorOutput.RegressionMetrics.Sum(metric => metric.Rms);
Console.WriteLine($"Average R^2: {totalR2 / crossValidatorOutput.RegressionMetrics.Count}");
Console.WriteLine($"Average RMS: {totalRMS / crossValidatorOutput.RegressionMetrics.Count}");
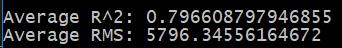
So our cross validation got an average of 79.6% for R Squared and an average of almost 5800 for root mean squared. Remember what we got before when running the Evaluate method on our pipeline? Here’s a quick refresher.

Why is the cross validation off than what our initial evaluation said the performance was? It turns out that our model was overfitting a bit on our training data. What can we do to help overcome that? We could do some feature engineering, but perhaps the easiest thing to do is to just get more data to train on.
In this post, we went over what cross validation, how it can help you to determine the performance of your models, and how to do it in ML.NET. Now it’s time to cross validate all the things!
