
Project Overview
This customer is a leading supplier of data and analytics to measure and predict performance across product channels, receiving and evaluating point-of-sale data from over 600,000 retail locations and millions of receipts from 130,000 customers. They track and analyze more than 3 billion records each week to deliver insights and forecasts.
After years of running their own on-premise datacenters, this customer decided to move all operations to Azure as part of multi-year cloud transformation plan. The customer was forecasting continued, rapid customer growth which would increase the number of active users to over 20,000. In addition, the teams were having trouble keeping up with the continuous need for new hardware to process more than 2 Petabytes of information curated over 15 years. Despite having more than 2,400 cores for processing, the teams struggled to produce the required monthly analytics reports on schedule. As the size of the organization had grown, numerous teams were competing for access to the resources needed to analyze and process new data for these reports. The customer recognized the elasticity of the cloud could provide a solution to these issues.
Wintellect was asked to examine both the applications and the data platform, to create the go-forward architecture, and to plan a roadmap for the cloud migration and transformation, leveraging the Microsoft Cloud Adoption Framework (CAF). As part of this transformation, the customer was interested in reimagining the current data processing platform and recreating it with a cloud-first, cloud-native approach. Wintellect led the effort, assisting the customer to implement an Azure Modern Data Warehouse.
Details
The solution design combined Azure Data Lake Storage (Gen 2), Azure Synapse Analytics (Spark and SQL pools), Azure Databricks, Azure SQL Database Hyperscale, Azure Analysis Services, and Power BI. This design reduces the time required to process large volumes of data, eliminated manual server maintenance, and improved the delivery of analytics to internal users and external customers. Wintellect helped the customer to define a multi-year roadmap for the new environment, plan the decommissioning of the current data centers, migrate data to the cloud, and prove out performance and cost savings. The proposed solution is expected to save the customer more than $20M per year, enabling the customer to explore new lines of business and allowing them to scale on demand.
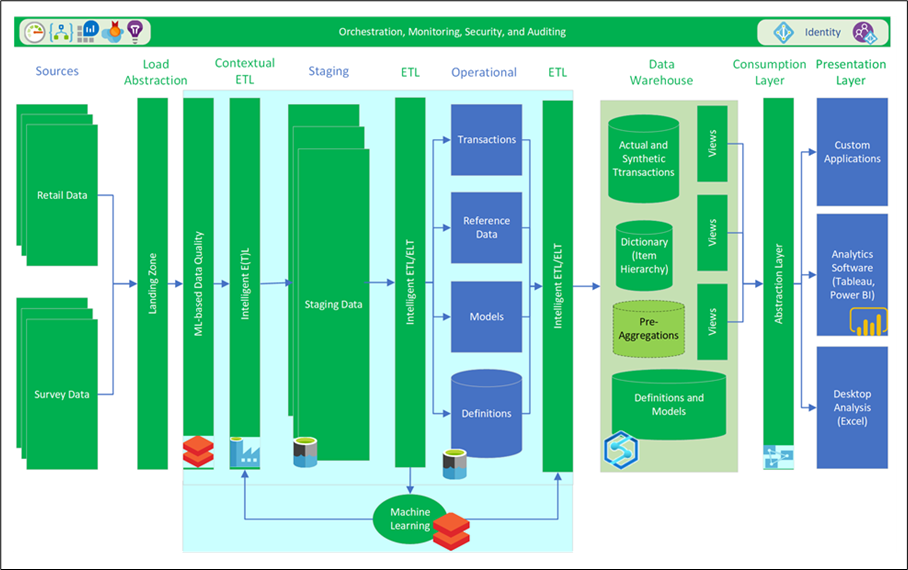
Figure 1. Overall system architecture
Networking and ExpressRoute Infrastructure
To facilitate the transfer of data from the on-premises systems and to extend the data into the cloud, an ExpressRoute was deployed. This provided dedicated bandwidth for the connectivity between Azure and the data centers, eliminating security concerns with transferring information between the two environments. This also simplified the process of deploying new systems into the Azure environment, allowing internal users to add scale on demand without having to purchase new hardware.
Data Lake Storage
The customer needed to store and access large volumes of historical and recent data and was moving from an existing Hadoop-based system. Utilizing Azure Data Lake Storage (Gen 2), Wintellect was able to provide the customer with virtually unlimited storage for organizing and analyzing their data. This further enabled the data to be structured to maximize the ability of teams to process and utilize the data for machine learning, analysis, processing, and loading.
Processing Data with Azure Synapse Analytics
Preparing, processing, and serving large amounts of data requires an engine that supports virtually limitless scale and massively parallel processing (MPP). Wintellect took advantage of Spark pools in Azure Synapse Analytics to quickly ingest high volumes of data, process and explore that data in-memory, and transform it as it moved from the data lake into tables. This enabled further processing of the data warehouse using native T-SQL tools with full MPP support. With the data loaded into tables, the customer could then transfer this data to semantic data models in Azure Analysis Services, enabling the content to be consumed at scale and presented using Power BI, Tableau, or through their own custom applications.
Integrated Machine Learning
Part of the secret behind the customer’s success is the ability of their data science team to derive new insights using machine learning and apply that to the data during ingestion, transformation, and consumption. Wintellect recommended the customer utilize a Data Lakehouse model to enable the data to be analyzed directly in the lake, enabling real-time analysis of both incoming and historical data. Combined with Azure Databricks, the data science team could prep data, build, deploy, and manage ML models at scale. Combined with the ability to consume a model directly and do batch scoring in Azure Synapse Analytics with TSQL or Apache Spark Pools, the process was designed to enable the customer to version and productionize their ML models.
High Concurrency with Azure SQL Database Hyperscale
One challenge which faced the customer was the need to have a high-performance database which could be used to support the needs of hundreds of concurrent users responsible for managing the core data used by the application. This data required tens of terabytes of storage and the ability to scale up to support high concurrent read activity without impacting the constant stream of updates to the incoming data. Utilizing additional read-only replicas for the queries made it possible for consistent high transaction volumes and low latencies. In addition, Wintellect was able to demonstrate that by optimizing the database design, they could meet or exceed the performance of the existing on-premises database system while achieving an 88% reduction in the number of cores required.
The Polyglot Experience
Key to the architecture of a modern data warehouse is a polyglot approach to data storage. This means using the service or tool that best supports the intended operations, with the data activities utilizing a broad array of services to maximize the overall performance. To hide the complexities of the underlying systems and to simplify application development, Wintellect proposed an API layer to separate the data services from the applications which require access. This enables the data to be accessed and stored in the most efficient and performance manner available, while at the same time creating a simple, developer-friendly interface to the stored data. This design pattern optimizes the data access, while at the same time reducing the learning curve required for the application development teams.
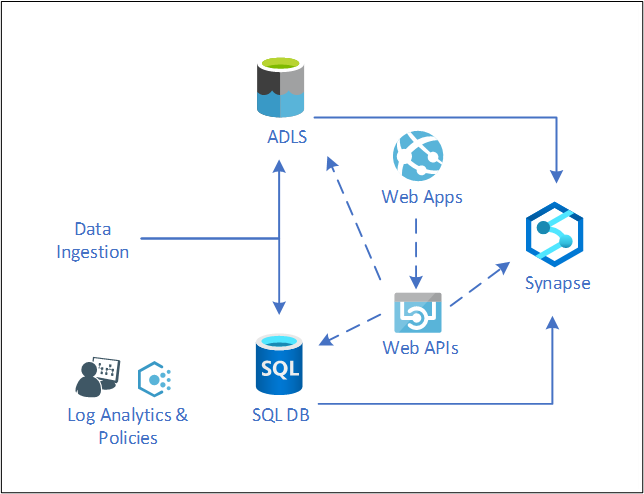
Figure 2. Polyglot data storage and APIs.
Ongoing Learning
For a team used to on-premises systems, the transition to the cloud can be overwhelming. To ensure success, teams need to learn new skills and new ways of working. By developing an understanding of the new environment, employees can experience enhanced productivity and more efficiently design, manage, and operate cloud-scale systems. Wintellect provided both Microsoft Official Curriculum (MOC) training and custom-developed, hands-on labs to ensure that the customer’s teams were able to take ownership of their Azure environment and continue their deployments to the cloud.
Why Wintellect?
The customer needed a partner that was expert at providing the architectural skills needed to combine complex business logic and petabyte-scale data into a technical design that was flexible and performant, as well as the implementation expertise required to implement the system.
- Wintellect has deep experience in developing intelligent and configurable decision solutions.
- Wintellect is a Microsoft Gold Cloud Platform, Application Development, Data Platform, Data Analytics, and DevOps partner
- Wintellect is a recognized leader in software architecture and implementation on the web, mobile, and cloud platforms.
Conclusion
The customer is expecting to eliminate more than 2,000 cores of on-premises virtual machines and their supporting hardware, replacing them with a modern data warehouse and leading to cost savings of more than $20M dollars per year. In addition, by optimizing the data architecture, schemas, and application design, the customer anticipated being able to reduce the total number of systems required to process their data by more than 75%. With less time spent managing hardware and infrastructure, the customer expected to spend more time on innovation and new business development.
